TPUs for deep learning
TPUs for deep learning
Project goal
CERN is running pilot projects to investigate the potential of hardware accelerators, using a set of LHC workloads. In the context of these investigations, this project focuses on the testing and optimisation of machine-learning and deep-learning algorithms on Google TPUs. In particular, we are focusing on generative adversarial networks (GANs).
Collaborators

Project background
The high-energy physics (HEP) community has a long tradition of using neural networks and machine-learning methods (random forests, boosted decision trees, multi-layer perceptrons) to solve specific tasks. In particular, they are used to improve the efficiency with which interesting particle-collision events can be selected from the background. In the recent years, several studies have demonstrated the benefits of using deep learning (DL) to solve typical tasks related to data taking and analysis. Building on these examples, many HEP experiments are now working to integrate deep learning into their workflows for many different applications (examples include data-quality assurance, simulation, data analysis, and real-time selection of interesting collision events). For example, generative models, from GANs to variational auto-encoders, are being tested as fast alternatives to simulation based on Monte Carlo methods. Anomaly-detection algorithms are being explored to improve data-quality monitoring, to design searches for rare new-physics processes, and to analyse and prevent faults in complex systems (such as those use for controlling accelerators and detectors).
The training of models such as these has been made tractable with the improvement of optimisation methods and the availability of dedicated hardware that is well adapted to tackling the highly parallelisable task of training neural networks. Storage and HPC technologies are often required by these kinds of projects, together with the availability of HPC multi-architecture frameworks (from large multi-core systems to hardware accelerators like Google TPUs).
Recent progress
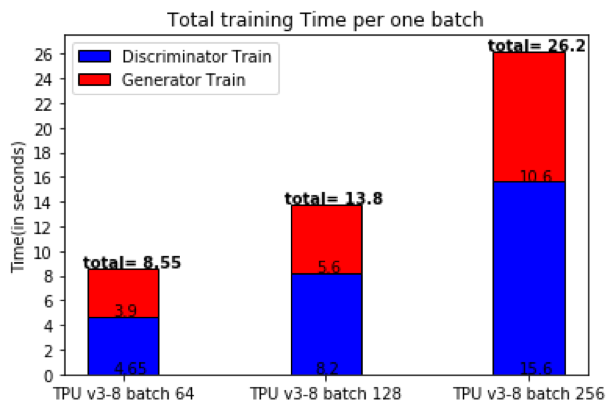
Machine learning has been used in a wide range of areas. Nevertheless, the need to make it faster while still maintaining accuracy (and thus the validity of results) is a growing problem for data scientists. Our work is exploring the Tensorflow distributed parallel strategy approach, in order to efficiently run a GAN model in a parallel environment. This includes benchmarking different types of hardware for such an approach.
Specifically, we parallelised a 3D convolutional GAN training process on multiple GPUs and multiple Google TPU cores. This involved two main approaches to the Tensorflow mirrored strategy:
The first approach uses the default implementation and the built-in logic from the Tensorflow strategy deployment model, with training on several GPUs.The second approach uses a custom training loop that we optimised in order to increase control over the training process, as well as adding further elements to each GPU’s work, increasing the overall speedup.
For the TPUs, we used the TPU distributed strategy present in Tensorflow, applying the same approaches as described for the mirrored strategy. This was validated by comparing with the results obtained with the original 3DGAN model, as well as the Monte Carlo simulated data. Additionally, we tested scalability over multiple GPU nodes by deploying the training process on different public cloud providers using Kubernetes.
Next steps
Presentations
- R. Cardoso, Accelerating GAN training using distributed tensorflow and highly parallel hardware (22 October). Presented at the 4th IML workshop, Geneva, 2020. cern.ch/go/H6xt